
数据预处理
中心化(零均值)
中心化就是零均值化,对于每一个元素减去本图像的平均值即可。
这样做的意义在于,对于某些激活函数,比如sigmoid,relu,tanh而言,激活函数单调递增,其任意一点导数均大于零。
而f关于wi的偏导数为xi,如果xi均为正数(或者负数),那么
其正负等同于xi的正负,也就是必然是正数(或者零)。
那么如果想要使得loss函数减小,朝着
的方向运动的话,就会出现只能朝着每一个wi的正方向或者负方向运动的情况。如果有n个wi的向量,则有2^n个象限,除非最优化wi就在全为正的第一象限,否则优化本身必然比较曲折。
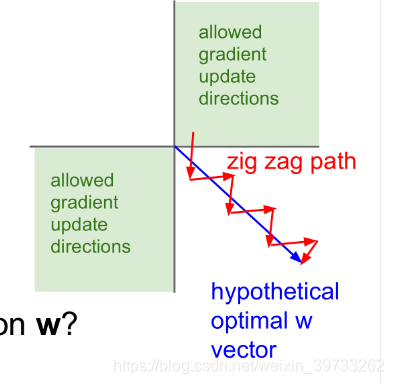
会反复向正方向运行收敛。如果此时纵坐标可以向负方向运动,则可以直接到达最优化点。
所以我们进行零均值化,当x正负数量“差不多”时,那么梯度的变化方向就会不确定,这样就能达到上图中的变化效果,加速了权重的收敛。
归一化
归一化是指将原始数据通过线性变化转换为范围在[0, 1]或[-1, 1]之间的数。
范围在[0,1 ]变换公式如下:
其中,min为最小值,max为最大值。
范围在[-1, 1]之间的变换公式如下:
其中,μ为最均值,max为最大值。
标准化
标准化也叫Z-Score标准化,是指将原始数据转化为均值为0,标准差为1的数据集,经过标准化处理的数据符合标准的正态分布,变换公式如下:
其中μ为数据集的平均值,δ为数据集的标准差。
标准化和归一化的目的
归一化/标准化可以去除数据单位对计算带来的影响,也就是所谓的去量纲行为,归一化/标准化实质是一种线性变换,线性变换有很多良好的性质,这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现,这些性质是归一化/标准化的前提。
归一化/标准化的去量纲作用能够带来以下两个好处:
- 提升模型的精度。一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
- 提高收敛速度。对于线性模型来说,数据归一化/标准化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。如下图所示:
图像数据扩增
若增加训练数据,则能够提升算法的准确率,因为这样可以避免过拟合,更好地泛化;而避免了过拟合你就可以增大你的网络结构了。
可以大量使用数据增广。
- 几何变换
包括:弹性变换(Elastic Transform)、透视变换(Perspective Transform)、分段仿射变换(Piecewise Affine transforms)、枕形畸变(Pincushion Distortion)。
- 随机改变大小(resize),随机缩放、旋转、翻转
- 从原始图像(256,256)中,随机的crop出一些图像(224,224)
不做随机crop,大型网络基本都过拟合(under substantial overfitting)。
- 水平/竖直翻转,flip。mirror,即水平翻转图像
- Rotation变换/旋转变换
- 加噪声
对主成分做一个(0, 0.1)的高斯扰动。
torchvision 中的数据扩增方法
torchvision.transforms中的数据扩增方法是针对于PIL图片
CenterCrop(size)
Crops the given PIL Image at the center.
size (sequence or int) – Desired output size of the crop. If size is an int instead of sequence like (h, w), a square crop (size, size) is made.
ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)
Randomly change the brightness, contrast and saturation of an image.
随机改变图像的亮度、对比度、饱和度、色调
FiveCrop(size)
Crop the given PIL Image into four corners and the central crop
size (sequence or int) – Desired output size of the crop. If size is an int instead of sequence like (h, w), a square crop of size (size, size) is made.
NOTE:
This transform returns a tuple of images and there may be a mismatch in the number of inputs and targets your Dataset returns. See below for an example of how to deal with this.
Grayscale(num_output_channels=1)
Convert image to grayscale.
num_output_channels (int) – (1 or 3) number of channels desired for output image
Pad(padding, fill=0, padding_mode=’constant’)
Pad the given PIL Image on all sides with the given “pad” value.
padding (int or tuple) – Padding on each border. If a single int is provided this is used to pad all borders. If tuple of length 2 is provided this is the padding on left/right and top/bottom respectively. If a tuple of length 4 is provided this is the padding for the left, top, right and bottom borders respectively.
fill (int or tuple) – Pixel fill value for constant fill. Default is 0. If a tuple of length 3, it is used to fill R, G, B channels respectively. This value is only used when the padding_mode is constant
padding_mode (str) –
Type of padding. Should be: constant, edge, reflect or symmetric. Default is constant.
constant: pads with a constant value, this value is specified with fill
edge: pads with the last value at the edge of the image
reflect: pads with reflection of image without repeating the last value on the edge
For example, padding [1, 2, 3, 4] with 2 elements on both sides in reflect mode will result in [3, 2, 1, 2, 3, 4, 3, 2]
symmetric: pads with reflection of image repeating the last value on the edge
For example, padding [1, 2, 3, 4] with 2 elements on both sides in symmetric mode will result in [2, 1, 1, 2, 3, 4, 4, 3]
RandomAffine(egrees, translate=None, scale=None, shear=None, resample=False, fillcolor=0)
Random affine transformation of the image keeping center invariant
RandomApply(transforms,p=0.5)
Apply randomly a list of transformations with a given probability
RandomChoise(transforms)
Apply single transformation randomly picked from a list
RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode=’constant’)
Crop the given PIL Image at a random location.
size (sequence or int) – Desired output size of the crop. If size is an int instead of sequence like (h, w), a square crop (size, size) is made.
padding (int or sequence**, optional) – Optional padding on each border of the image. Default is None, i.e no padding. If a sequence of length 4 is provided, it is used to pad left, top, right, bottom borders respectively. If a sequence of length 2 is provided, it is used to pad left/right, top/bottom borders, respectively.
pad_if_needed (boolean) – It will pad the image if smaller than the desired size to avoid raising an exception. Since cropping is done after padding, the padding seems to be done at a random offset.
fill – Pixel fill value for constant fill. Default is 0. If a tuple of length 3, it is used to fill R, G, B channels respectively. This value is only used when the padding_mode is constant
padding_mode –
Type of padding. Should be: constant, edge, reflect or symmetric. Default is constant.
constant: pads with a constant value, this value is specified with fill
edge: pads with the last value on the edge of the image
reflect: pads with reflection of image (without repeating the last value on the edge)
padding [1, 2, 3, 4] with 2 elements on both sides in reflect mode will result in [3, 2, 1, 2, 3, 4, 3, 2]
symmetric: pads with reflection of image (repeating the last value on the edge)
padding [1, 2, 3, 4] with 2 elements on both sides in symmetric mode will result in [2, 1, 1, 2, 3, 4, 4, 3]
RandomGrayscale(p=0.1)
Randomly convert image to grayscale with a probability of p (default 0.1).
p (float) – probability that image should be converted to grayscale.
RandomHorizontalFlip(p=0.5)
Horizontally flip the given PIL Image randomly with a given probability.
p (float) – probability of the image being flipped. Default value is 0.5
RandomOrder(transforms)
Apply a list of transformations in a random order
RamdomPerspective(distortion_scale=0.5, p=0.5, interpolation=3)
Performs Perspective transformation of the given PIL Image randomly with a given probability.
透视变换
- interpolation – Default- Image.BICUBIC
- p (float) – probability of the image being perspectively transformed. Default value is 0.5
- distortion_scale (float) – it controls the degree of distortion and ranges from 0 to 1. Default value is 0.5.
RandomSizeCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2)
Crop the given PIL Image to random size and aspect ratio.
A crop of random size (default: of 0.08 to 1.0) of the original size and a random aspect ratio (default: of 3/4 to 4/3) of the original aspect ratio is made. This crop is finally resized to given size. This is popularly used to train the Inception networks.
- size – expected output size of each edge
- scale – range of size of the origin size cropped
- ratio – range of aspect ratio of the origin aspect ratio cropped
- interpolation – Default: PIL.Image.BILINEAR
RandomRotation(degrees, resample=False, expand=False, center=None)
Rotate the image by angle.
- degrees (sequence or float or int) – Range of degrees to select from. If degrees is a number instead of sequence like (min, max), the range of degrees will be (-degrees, +degrees).
- resample ({PIL.Image.NEAREST**, PIL.Image.BILINEAR**, PIL.Image.BICUBIC},optional) – An optional resampling filter. See filters for more information. If omitted, or if the image has mode “1” or “P”, it is set to PIL.Image.NEAREST.
- expand (bool, optional) – Optional expansion flag. If true, expands the output to make it large enough to hold the entire rotated image. If false or omitted, make the output image the same size as the input image. Note that the expand flag assumes rotation around the center and no translation.
- center (2-tuple**, optional) – Optional center of rotation. Origin is the upper left corner. Default is the center of the image.
RandomVerticalFilp(p=0.5)
Vertically flip the given PIL Image randomly with a given probability.
p (float) – probability of the image being flipped. Default value is 0.5
Resize(size, interpolation=2)
Resize the input PIL Image to the given size.
- size (sequence or int) – Desired output size. If size is a sequence like (h, w), output size will be matched to this. If size is an int, smaller edge of the image will be matched to this number. i.e, if height > width, then image will be rescaled to (size * height / width, size)
- interpolation (int, optional) – Desired interpolation. Default is
PIL.Image.BILINEAR
TenCrop(size, vertical_flip=False)
Crop the given PIL Image into four corners and the central crop plus the flipped version of these (horizontal flipping is used by default)
- size (sequence or int) – Desired output size of the crop. If size is an int instead of sequence like (h, w), a square crop (size, size) is made.
- vertical_flip (bool) – Use vertical flipping instead of horizontal
Normalize(mean, std, inplace=False)
这是针对于Tensor的函数
Normalize a tensor image with mean and standard deviation. Given mean: (M1,...,Mn) and std: (S1,..,Sn) for n channels, this transform will normalize each channel of the input torch.*Tensor i.e. input[channel] = (input[channel] - mean[channel]) / std[channel]
- mean (sequence) – Sequence of means for each channel.
- std (sequence) – Sequence of standard deviations for each channel.
- inplace (bool,**optional) – Bool to make this operation in-place.
ToPILImage(mode=None)
将Tensor格式图片或者numpy格式图片转化为PIL格式图片
Convert a tensor or an ndarray to PIL Image.
Converts a torch.*Tensor of shape C x H x W or a numpy ndarray of shape H x W x C to a PIL Image while preserving the value range.
mode (PIL.Image mode) –
color space and pixel depth of input data (optional). If mode is None (default) there are some assumptions made about the input data:
- If the input has 4 channels, the
modeis assumed to beRGBA.- If the input has 3 channels, the
modeis assumed to beRGB.- If the input has 2 channels, the
modeis assumed to beLA.- If the input has 1 channel, the
modeis determined by the data type (i.eint,float,short).
Totensor()
将PILImage或者numpy图片转化为tensor
Convert a PIL Image or numpy.ndarray to tensor.
Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0] if the PIL Image belongs to one of the modes (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1) or if the numpy.ndarray has dtype = np.uint8
In the other cases, tensors are returned without scaling.

