
深度学习之GPU和显存分析
预备知识
nvidia-smi是Nvidia显卡命令行管理套件,基于NVML库,旨在管理和监控Nvidia GPU设备.
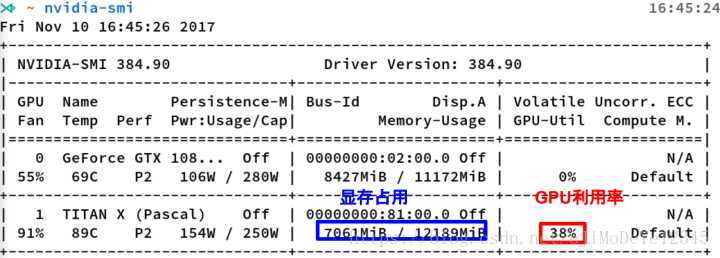
这是nvidia-smi命令的输出,其中最重要的两个指标:
- 显存占用
- GPU利用率
- 显存占用和GPU利用率是两个不一样的东西,显卡是由GPU计算单元和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。
推荐工具:gpustat
pip install gpustat |

- 显存可以看成是空间,类似于内存。
- 显存用于存放模型,数据
- 显存越大,所能运行的网络也就越大
- GPU计算单元类似于CPU中的核,用来进行数值计算。衡量计算量的单位是flop: the number of floating-point multiplication-adds,浮点数先乘后加算一个flop。计算能力越强大,速度越快。衡量计算能力的单位是flops: 每秒能执行的flop数量
1*2+3 1 flop |
显存分析
1Byte = 8 bit |
除了K、M,G,T等之外,我们常用的还有KB 、MB,GB,TB 。二者有细微的差别。
1Byte = 8 bit |
Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用4Byte的显存。
举例来说:有一个1000x1000的 矩阵,float32,那么占用的显存差不多就是
1000x1000x4 Byte = 4MB
32x3x256x256的四维数组(BxCxHxW)占用显存为:24M
神经网络显存占用
神经网络模型占用的显存包括:
- 模型自身的参数
- 模型的输入输出
举例来说,对于如下图所示的一个全连接网络(不考虑偏置项b)
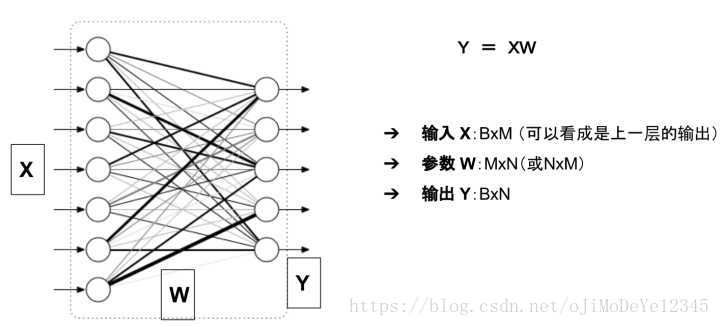
模型的输入输出和参数
模型的显存占用包括:
- 参数:二维数组 W
- 模型的输出: 二维数组 Y
输入X可以看成是上一层的输出,因此把它的显存占用归于上一层。
这么看来显存占用就是W和Y两个数组?
并非如此!!!
只有有参数的层,才会有显存占用。这部份的显存占用和输入无关,模型加载完成之后就会占用。
有参数的层主要包括:
- 卷积
- 全连接
- BatchNorm
- Embedding层
- … …
无参数的层:
- 多数的激活层(Sigmoid/ReLU)
- 池化层
- Dropout
- … …
Linear(M->N): 参数数目:M×N
Conv2d(Cin, Cout, K): 参数数目:Cin × Cout × K × K
BatchNorm(N): 参数数目: 2N
Embedding(N,W): 参数数目: N × W
参数占用显存 = 参数数目×n
n = 4 :float32
n = 2 : float16
n = 8 : double64
在PyTorch中,当你执行完model=MyGreatModel().cuda()之后就会占用相应的显存,占用的显存大小基本与上述分析的显存差不多(会稍大一些,因为其它开销)。
梯度与动量的显存占用
举例来说, 优化器如果是SGD:
可以看出来,除了保存W之外还要保存对应的梯度∇F(W) ,因此显存占用等于参数占用的显存x2,
如果是带Momentum-SGD
这时候还需要保存动量, 因此显存x3
如果是Adam优化器,动量占用的显存更多,显存x4
输入输出的显存占用
这部份的显存主要看输出的feature map 的形状。
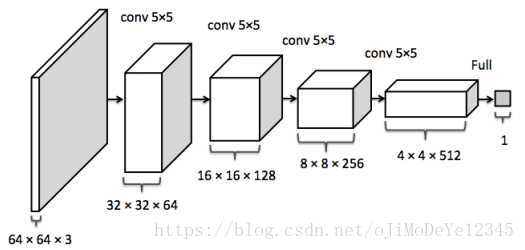
据此可以计算出每一层输出的Tensor的形状,然后就能计算出相应的显存占用。
深度学习中神经网络的显存占用,我们可以得到如下公式:
显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用 |
AlexNet 分析
AlexNet的分析如下图,左边是每一层的参数数目(不是显存占用),右边是消耗的计算资源

可以看出:
- 全连接层占据了绝大多数的参数
- 卷积层的计算量最大

